| edit | ||
| errutil | ||
| eval | ||
| parse | ||
| samples | ||
| screenshots | ||
| store | ||
| strutil | ||
| sys | ||
| sysutil | ||
| .gitattributes | ||
| .gitignore | ||
| .travis.yml | ||
| Dockerfile | ||
| LICENSE | ||
| main.go | ||
| Makefile | ||
| README.md | ||
An experimental Unix shell
This is a work in progress. Things may change and/or break without notice. You have been warned...
Fancy badges:


Obligatory screenshots
I love software websites without screenshots of the actual thing. -- No one ever
Syntax highlighting (also showcasing right-hand-side prompt):

Tab completion for files:

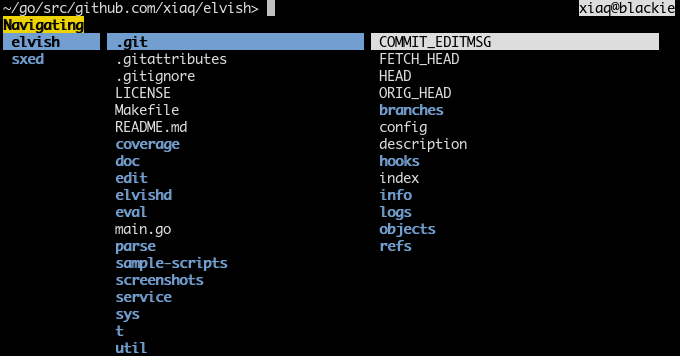
Navigation mode (triggered with ^N, inspired by ranger):
Building
Go >= 1.4 is required. This repository is a go-getable package.
Linux is fully supported. I also try to ensure that it compiles on FreeBSD, which means it will also likely compile on other BSDs and Mac OS X. Windows is not yet supported, but it might be in future.
In case you are new to Go, you are advised to read How To Write Go Code, but here is a quick snippet:
export GOPATH=$HOME/go
export PATH=$PATH:$GOPATH/bin
go get github.com/elves/elvish
elvish
To update and rebuild:
go get -u github.com/elves/elvish
Remember to put the two exports above into your bashrc or zshrc (or
whatever).
Archlinux users can also try the AUR package elvish-git.
Notes for Contributors
Testing
Always run unit tests before committing. make will take care of this.
Generated files
Some files are generated from other files. They should be commmited into the
repository for this package to be go-getable. Run make pre-commit to
re-generate them in case you modified the source. Read the Makefile for
details.
Formatting the Code
Always format the code with goimports before committing. Run
go get code.google.com/p/go.tools/cmd/goimports to install goimports, and
goimports -w . to format all golang sources.
To automate this you can set up a goimports filter for Git by putting this
in ~/.gitconfig:
[filter "goimports"]
clean = goimports
smudge = cat
.gitattributes in this repository refers to this filter. Read more about Git
attributes and filters
here.
Licensing
By contributing, you agree to license your code under the same license as existing source code of Elvish. See the License section.
Name
In rogue-likes, items made by the elves have a reputation of high quality. These are usually called elven items, but I chose elvish for obvious reasons.
The adjective for elvish is also "elvish", not "elvishy" and definitely not "elvishish".
I am aware of the fictional elvish language, but I believe there is not much room for confusion and the google-ability is still pretty good.
The Editor
Those marked with ✔ are implemented (but could be broken from time to time).
Like fish:
- Syntax highlighting ✔
- Auto-suggestion
Like zsh:
- Right-hand-side prompt ✔
- Dropdown menu completion ✔
- Programmable line editor
And:
- A vi keybinding that makes sense
- More intuitive multiline editing
- Some method to save typed snippets into a script
- A navigation mode for easier casual exploration of directories ✔
The Language
(Like the previous section, only those marked with ✔ have been implemented.)
-
Running external programs and pipelines, of course (
~>represents the prompt): ✔~> vim README.md ... ~> cat -v /dev/random ... ~> dmesg | grep bar ... -
Some constructs look like lisp without the outermost pair of parentheses: ✔
~> + 1 2 ▶ 3 ~> * (+ 1 2) 3 ▶ 9 -
Use backquote for literal string (so that you can write both single and double quotes inside), double backquotes for a literal backquote: ✔
~> echo `"He's dead, Jim."` "He's dead, Jim." ~> echo `````He's dead, Jim."` ``He's dead, Jim." -
Barewords are string literals: ✔
~> = a `a` ▶ $true -
Tables are a hybrid of array and hash (a la Lua); tables are first-class values: ✔
~> println [a b c &key value] [a b c &key value] ~> println [a b c &key value][0] a ~> println [a b c &key value][key] value -
Declare variable with
var, set value withset;varalso serve as a shorthand of var-set combo: ✔~> var $v table ~> set $v = [foo bar] ~> var $u table = [foo bar] # equivalent -
First-class closures, lisp-like functional programming:
~> map {|$x| * 2 $x} [1 2 3] [2 4 6] ~> filter {|$x| > $x 2} [1 2 3 4 5] [3 4 5] ~> map {|$x| * 2 $x} (filter {|$x| > $x 2} [1 2 3 4 5]) [6 8 10] -
Get rid of lots of irritating superfluous parentheses with pipelines (
putis the builtin for outputting compound data):~> put 1 2 3 4 5 | filter {|$x| > $x 2} | map {|$x| * 2 $x} 6 8 10 -
Use the
env:namespace for environmental variables: ✔~> put $env:HOME ▶ /home/xiaq ~> set $env:PATH = $env:PATH`:/bin`
There are many parts of the language that is not yet decided. The issues list contain many of things I'm currently thinking about.
Motivation
This experiment has a number of motivations. Some of them:
-
It attempts to prove that a shell language can be a handy interface to the operating system and a decent programming language at the same time; Many existing shells recognize the former but blatantly ignore the latter.
-
It attempts to build a better interface to the operating system, trying to strike the right balance between the tool philosophy of Unix and the tremendous usefulness of a more integrated system.
-
It also attempts to build a better language, learning from the success and failure of programming language designs.
-
It attempts to exploit a facility Shell programmers are very familiar with, but virtually unknown to other programmers - the pipeline. That leads us to the topic of the next few sections.
The power of pipelines
A Concatenative Programming Facility
Pipelines make for a natural notation of concatenative programming.
So what's concatenative programming? In some of its most common use cases, we
can say it's just functional programming without lots of irritating
superfluous parentheses. Consider this fictional piece
of lisp to find in strs, a list of strings, all members containing "LOL",
transform them into upper case, sort them, and store them in another list
lols:
(def lols (sort (map upper-case
(filter (lambda (x) (contains? x "LOL")) strs))))
(See Appendix A for this piece of code in real lisps.)
It looks OK until you try to read the code aloud:
Put in
lolswhat results from sorting what results from turning into upper case what results from filtering the strings that contain "LOL" instrs.
An deep hierarchy of parentheses map into a deep hierarchy of clauses. Worse, this reads backwards.
What would you do it in shell, with pipelines? Assuming that the strings are
stored in the file strs, it is just:
lols=`cat strs | grep LOL | tr a-z A-Z | sort`
The historically weird names aside, it reads perfectly natural: assign to
lols the result of the following: take the lines in strs, find those
having "LOL", change them to upper case, and sort them. This matches our
description of the procedure except for the assignment. There is an obvious
restriction with this shell pipeline approach, but that will be the topic of
the next section.
Concatenative programming is the notion of building programs by connecting
data-transforming constructs together. In our case, the constructs are cat strs, grep LOL, tr a-z A-Z and sort; the pipe symbol is the
connector. The interesting thing is that each construct itself is actually a
valid program; thus it could be said that a more complex program is formed by
concatenating simpler programs, hence the term "concatenative programming".
Compare this to the conventional ("applicative") approach, where constructs
are nested instead of connected one after another.
A Concurrency Construct
There is any thing that is particular about pipelines. Consider this piece of (very realistic) shell code:
tail -f access.log | grep x
If a line containing x ever gets appended to access.log, it will appear on
the console immediately. Every sysadmin knows that.
However, if you try implementing this in another other language, you will
quickly notice that this functionality is not trivial. The monitoring of
access.log and the filtering for x are going on at the same time.
Also consider this more subtle example:
cat *.go | grep .
This program concatenates all Go sources and filter out empty lines. Even if there are a lot of very large Go sources, this program will start pouring lines onto the terminal immediately. If we emulate the structure of this program - "cat, then grep" - with Python:
import sys
from glob import glob
# cat *.go
lines = []
for fname in glob('*.go'):
with open(fname) as f:
lines.extend(f.readlines())
# grep .
for line in lines:
if len(line) > 1:
sys.stdout.write(line)
There will be a hiatus in the presense of many large Go sources. To be
efficient, you have to interweave the logic of cat and grep:
import sys
from glob import glob
# cat *.go
for fname in glob('*.go'):
with open(fname) as f:
# grep .
for line in f:
if len(line) > 1:
sys.stdout.write(line)
However, in shell you separate cat and grep cleanly, yet their executions
are interweaved automatically. This is why we call pipelines a concurrency
construct: the components that make up a pipeline run concurrently and
there is really a pipe carrying data constantly flowing between them.
The drawbacks of traditional pipelines
Consider this seemingly correct program that finds all PNG files and sort them:
find . -name '*.png' | sort
It seems correct but is actually wrong. Suppose that the current directory
contains only two files called a\n.png and b\n.png (\n representing a
newline), the program will output the following:
./a
./b
.png
.png
This is because both find and sort treat newlines as data boundaries. When
the data itself contains newlines, the boundary is messed up.
Modern tools do provide workarounds for such problems. Although newlines are
perfectly legal in file names, \0 is not; with the -print0 option of
find and -z of sort, they can be taught to use \0 as the data
boundary.
find . -name '*.png' -print0 | sort -z
Which works, but it is always clumsy to (remember and) add these little
options. Worse, \0 typically shows up as nothing on the terminal, making it
even clumsier to debug such programs.
We have outlined one drawback of traditional pipelines: they assume that data is separated by newline, which is not always true. Now instead of looking at the boundaries of data, we consider the data themselves. Consider the following series of tasks:
-
Find all lines in the file
strscontaininglol. This is trivial (the useless use ofcatis there for a reason):cat strs | grep lol -
Find all lines in the file
records, where each line consists of space-separated columns, whose second column containslol. This is possible with the help ofawk:cat records | awk '{ if (match($2, /lol/)) print; }' -
Find all lines in the file
jsons, where each line is a JSON object, whosenameattribute containslol. This is still possible with the amazing jq tool:cat jsons | jq -c 'select(.name | contains("lol"))'
Powerful as it seems, something is definitely going wrong here. Each type of complex data now requires a separate external tool, each with their own domain-specific language (DSL). As the complexity of the data grows, the part programmed in DSLs grows and the pipeline becomes almost superfluous. This brings us to the second drawback of traditional pipelines: they assume no to little internal structure of the data, which is again not always true.
Argubly, this drawback is partly a problem of tooling instead of the pipeline
itself. For some use cases, simple commands like cut, paste and join
work well for space-separated columns and there is no need for awk. However,
they are often clumsy to use - the problem is that these tools can only
communicate with each other with structureless lines, limiting their
combinatory power.
A richer pipeline
(To be written)
License
BSD 2-clause license. See LICENSE for a copy.
Appendix A
This fictional lisp code:
(def lols (sort (map upper-case
(filter (lambda (x) (contains? x "LOL")) strs))))
written in Clojure:
(require ['clojure.string :refer '(upper-case)])
(def strs '("aha" "LOLaha" "hahaLOL" "hum?"))
(def lols (sort (map upper-case
(filter #(re-find #"LOL" %) strs))))
written in Racket:
(define strs '("aha" "LOLaha" "hahaLOL" "hum?"))
(define lols (sort (map string-upcase
(filter (lambda (x) (regexp-match? #rx"LOL" x)) strs))
string<?))
The examples with Lisps are actually not very fair; thanks to the enormous
power of macros, in Lisps it is actually possible to write concatenative code.
For instance, Clojure has two macros, -> and ->> which "threads" an
expression through consecutive forms. The last line of the Clojure code above
can thus be rewritten as:
(def lols (->> strs (filter #(re-find #"LOL" %)) (map upper-case) (sort)))
Note that though this construct emulates concatenative programming well, the concurrency of pipelines is not emulated; under the hood the forms are executed serially. For concurrency constructs, one still need to resort other primitives.